Kimi-Audio
综合介绍
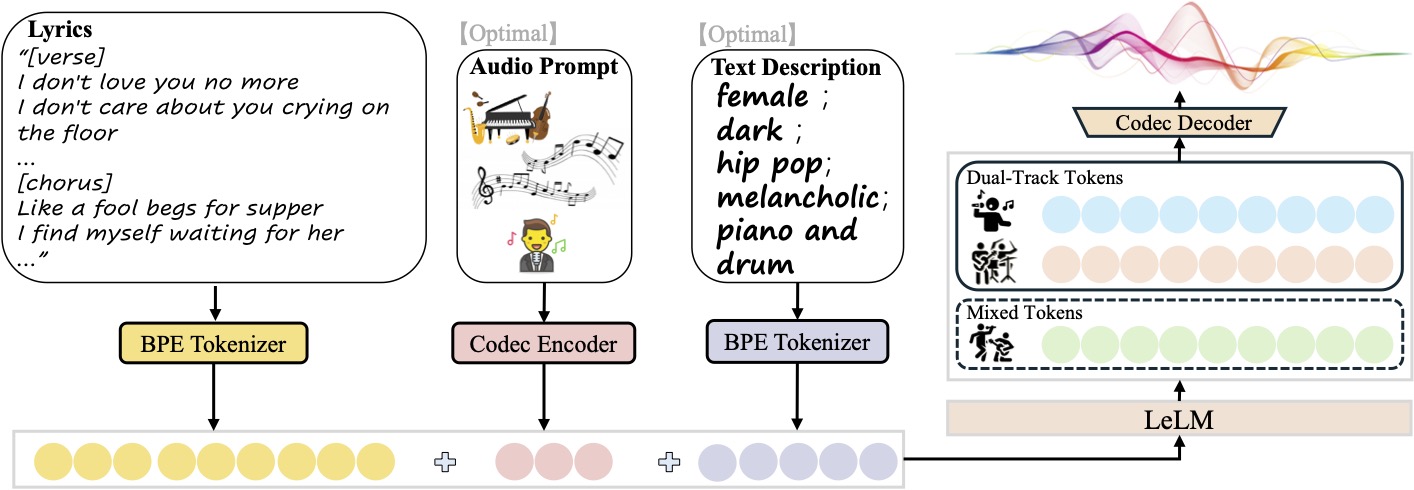
Kimi-Audio是月之暗面(Moonshot AI)公司开发的一个开源音频基础模型。这个工具主要用来处理各种和音频相关的任务,可以将它看作一个能听、能说、能理解多种音频内容的人工智能。它不仅能将语音准确转换成文字(语音识别),还能理解音频中的内容并回答问题(音频问答),甚至可以和用户进行流畅的语音对话。开发团队通过使用超过1300万小时的音频和文本数据对模型进行预训练,让它具备了强大的音频理解与语言处理能力。作为一个开源项目,开发者可以免费使用它的代码和模型,也可以根据自己的需求进行微调和二次开发,推动音频AI技术的研究和应用。
功能列表
- 通用音频处理: 在一个统一的框架内,支持多种音频任务,包括自动语音识别(ASR)、音频问答(AQA)、音频描述生成(AAC)和语音情绪识别(SER)等。
- 端到端语音对话: 支持从接收用户语音到生成语音回复的完整对话流程,实现流畅的语音交互体验。
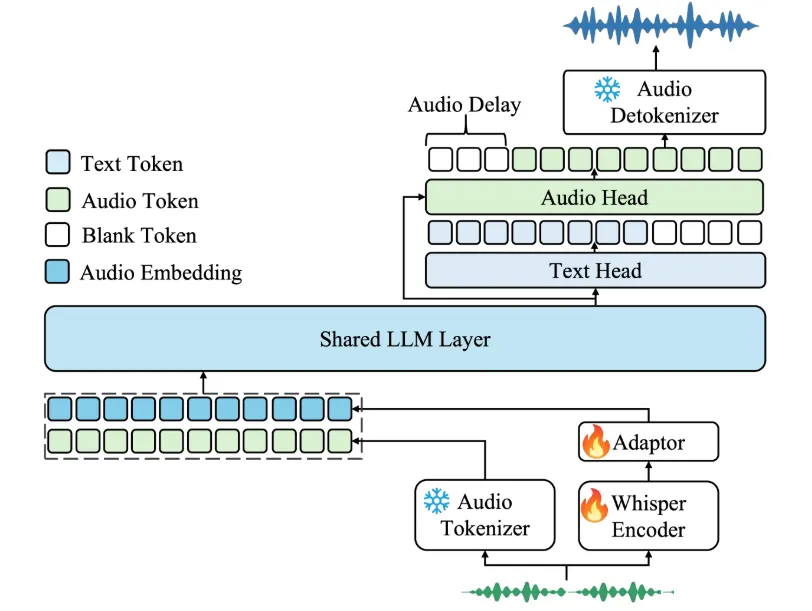
- 音频理解与生成: 模型采用独特的混合式音频输入,结合了连续的声学特征和离散的语义信息,并通过大语言模型进行处理,能同时生成文本和音频两种内容。
- 高效的推理性能: 音频生成部分采用了流式处理技术,可以在保证生成质量的同时,实现低延迟的实时语音输出,让对话更自然。
- 模型微调支持: 项目提供了预训练好的模型权重和轻量级的微调代码,方便开发者在特定任务或数据集上对模型进行优化。
- 开放的评估工具: 项目同时发布了一个名为
Kimi-Audio-Evalkit的评估工具包,用于标准化地测试和比较不同音频大模型的性能,确保了评估结果的公平性和可复现性。 - 多轮对话能力: 模型能够处理包含多轮问答的复杂对话场景,可以记忆和理解上下文信息,并作出符合逻辑的回复。
使用帮助
Kimi-Audio作为一个开源模型,为开发者提供了相对简单的安装和使用流程。下面将详细介绍如何在你的开发环境中配置并运行Kimi-Audio,以及如何使用它的核心功能。
环境安装
开始使用前,你需要一个支持Python的环境,并安装好PyTorch等依赖。官方推荐通过pip进行安装,这种方式可以自动处理大部分依赖项。
1. 克隆项目仓库首先,从GitHub上获取项目源代码。打开你的终端或命令行工具,输入以下命令:
git clone https://github.com/MoonshotAI/Kimi-Audio.git
接着,进入项目目录:
cd Kimi-Audio
然后,初始化并更新项目依赖的子模块:
git submodule update --init --recursive
2. 安装依赖库项目所需的所有Python库都记录在requirements.txt文件中。你可以使用pip命令一键安装:
pip install -r requirements.txt
另一种更直接的安装方式是直接通过pip从GitHub仓库安装,这种方法会自动处理依赖关系,包括torch:
pip install torch
pip install git+https://github.com/MoonshotAI/Kimi-Audio.git
安装完成后,你的环境就准备就绪了。
快速上手
下面通过几个代码示例,展示Kimi-Audio的主要功能如何使用。
1. 准备工作:加载模型无论进行何种操作,第一步都是加载Kimi-Audio模型。这里以官方发布的Kimi-Audio-7B-Instruct指令微调模型为例。
import soundfile as sf
from kimia_infer.api.kimia import KimiAudio
# 指定模型路径,这里使用Hugging Face上的模型名称
model_path = "moonshotai/Kimi-Audio-7B-Instruct"
# 初始化模型,如果需要生成音频,请将 load_detokenizer 设置为 True
model = KimiAudio(model_path=model_path, load_detokenizer=True)
2. 配置生成参数你可以通过调整采样参数来控制模型生成文本和音频的风格。
sampling_params = {
"audio_temperature": 0.8, # 音频温度,控制随机性
"audio_top_k": 10, # 音频Top-K采样
"text_temperature": 0.0, # 文本温度,设为0表示更确定的输出
"text_top_k": 5, # 文本Top-K采样
"audio_repetition_penalty": 1.0, # 音频重复惩罚
"text_repetition_penalty": 1.0, # 文本重复惩罚
}
3. 功能操作示例
- 示例一:语音转文字(ASR)这个例子演示了如何将一个WAV音频文件中的中文语音转换成文字。
# 准备输入消息列表,可以包含文本作为提示
messages_asr = [
{"role": "user", "message_type": "text", "content": "请转录以下音频:"},
{"role": "user", "message_type": "audio", "content": "test_audios/asr_example.wav"} # 替换为你的音频文件路径
]
# 调用生成接口,只生成文本
_, text_output = model.generate(messages_asr, **sampling_params, output_type="text")
print(f">>> ASR 输出文本: {text_output}")
# 预期输出: "这并不是告别,这是一个篇章的结束,也是新篇章的开始。"
- 示例二:语音对话(输入音频,输出文本和音频)这个例子中,用户输入一段包含问题的音频,模型会生成文本和语音两种格式的回答。
# 准备输入消息
messages_conversation = [
{"role": "user", "message_type": "audio", "content": "test_audios/qa_example.wav"} # 替换为你的提问音频
]
# 调用生成接口,同时生成音频和文本
wav_output, text_output = model.generate(messages_conversation, **sampling_params, output_type="both")
# 保存生成的音频文件
output_audio_path = "output_audio.wav"
sf.write(output_audio_path, wav_output.detach().cpu().view(-1).numpy(), 24000) # 模型输出的音频采样率为24kHz
print(f">>> 对话输出音频已保存至: {output_audio_path}")
print(f">>> 对话输出文本: {text_output}")
# 预期输出文本: "当然可以,这很简单。一二三四五六七八九十。"
- 示例三:多轮语音对话Kimi-Audio支持带有上下文的多轮对话。你需要将之前的对话历史(包括用户输入和模型的回复)一并传入。
# 构造一个包含历史记录的消息列表
messages_multiturn = [
# 第一轮用户提问
{"role": "user", "message_type": "audio", "content": "test_audios/multiturn/case2/multiturn_q1.wav"},
# 第一轮模型回答(包含音频和文本)
{"role": "assistant", "message_type": "audio-text", "content": ["test_audios/multiturn/case2/multiturn_a1.wav", "当然可以,这很简单。一二三四五六七八九十。"]},
# 第二轮用户提问
{"role": "user", "message_type": "audio", "content": "test_audios/multiturn/case2/multiturn_q2.wav"}
]
# 生成第二轮的回答
wav_output, text_output = model.generate(messages_multiturn, **sampling_params, output_type="both")
# 保存并打印输出
output_audio_path_multi = "output_multiturn_audio.wav"
sf.write(output_audio_path_multi, wav_output.detach().cpu().view(-1).numpy(), 24000)
print(f">>> 多轮对话输出音频已保存至: {output_audio_path_multi}")
print(f">>> 多轮对话输出文本: {text_output}")
# 预期输出文本: "没问题,继续数下去就是十一十二十三十四十五十六十七十八十九二十。"
通过以上步骤,你就可以在自己的项目中集成并使用Kimi-Audio的各项功能了。对于更高级的应用,例如模型微调,可以参考项目finetune_codes目录下的说明文档。
应用场景
- 智能语音助手可以作为智能音箱、车载系统或手机应用的核心,与用户进行自然的语音交流,理解并执行指令,如查询天气、播放音乐、设置提醒等。
- 会议内容分析在会议场景中,Kimi-Audio能够实时将会议录音转写为文字记录,并能进一步对内容进行摘要、提取关键决策和待办事项,大幅提升会议效率。
- 内容创作辅助为视频创作者或播客主播提供辅助。例如,它可以根据输入的文本草稿生成带情感的旁白音频,或者自动为视频内容添加准确的字幕。
- 语言学习与教育在语言学习软件中,Kimi-Audio可以扮演陪练角色,与学习者进行外语对话,并对发音、语法等提供即时反馈。同时,它也能将教学音频转换为文字材料,方便学生复习。
QA
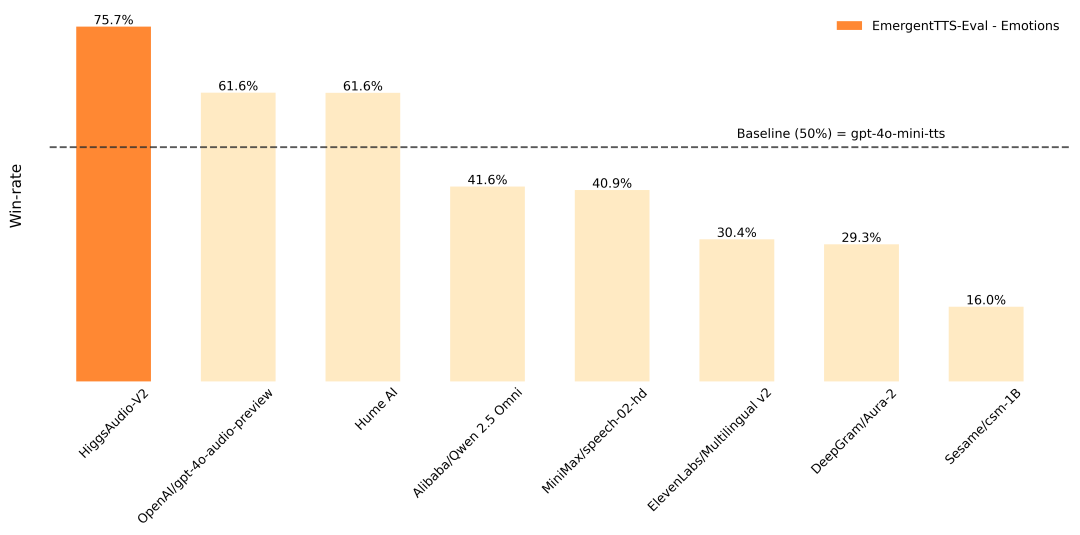
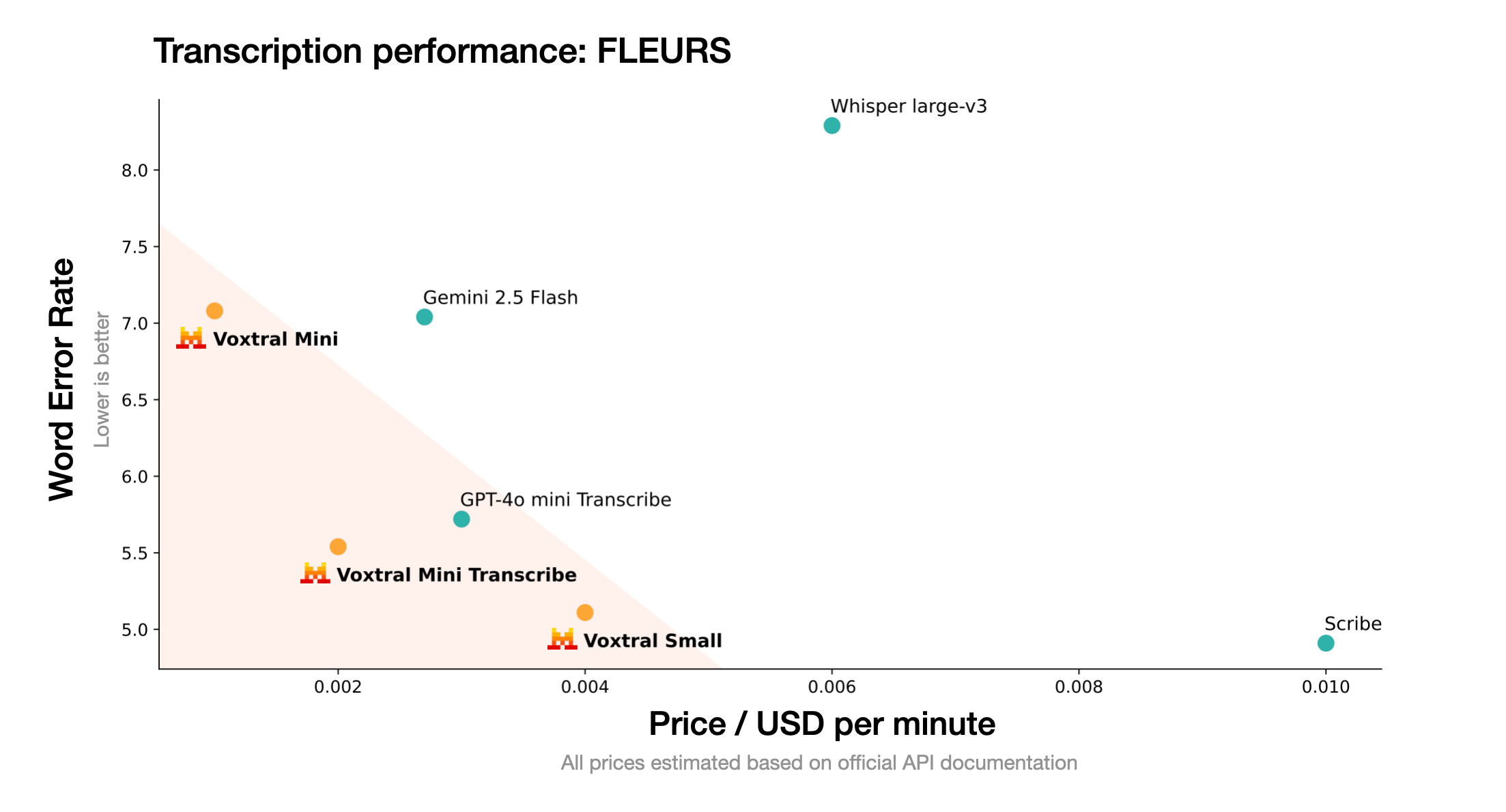
- Kimi-Audio支持哪些语言?根据项目文档和提供的示例,Kimi-Audio目前主要展示了在中文和英文上的强大能力,特别是在中文语音识别(ASR)方面达到了业界领先水平。其预训练数据包含多种语言,因此具备处理多语种任务的潜力。
- 使用Kimi-Audio需要什么样的硬件配置?作为一个基于7B(70亿参数)大语言模型的系统,运行Kimi-Audio需要较高的计算资源,特别是带较大显存的GPU(显卡)。具体的硬件需求取决于你是要进行推理(使用模型)还是微调(训练模型),微调需要更高的配置。详细信息通常可以在项目的issue或讨论区找到社区分享的经验。
- Kimi-Audio是完全免费的吗?是的,Kimi-Audio项目是开源的。它的代码主要使用MIT许可证,而部分基于Qwen2.5-7B模型的代码则遵循Apache 2.0许可证。这意味着个人开发者和企业都可以免费使用、修改和分发,但需要遵守相应开源协议的规定。
- 相比于其他音频模型(如GPT-4o),Kimi-Audio有什么优势?Kimi-Audio的主要优势在于它是一个完全开源的项目,为研究和开发社区提供了极大的灵活性。它在多个中文语音识别基准测试中表现出色,性能超过了一些同类模型。此外,项目专门推出了一个开放的评估工具包,致力于建立一个公平、透明的性能比较标准,推动整个领域的发展。